講到效能測試就必須將測試的程式碼抓到伺服器上,用編譯器編譯過後跑跑看花的時間,如果只是執行編譯好的測試程式就無法反應出實際上寫計算程式的開發者,所能發揮出來的硬體效能,因此第二部分的從簡單的平行計算介紹開始,以三個測試的例子來展示如何在四核心處理器上搭配Intel軟體來發揮整體的運算效能。
Part2 基本效能測試
平行計算簡介
如果讀者有撰寫過計算程式的經驗,就會知道大部分的理論推導出來後,想要透過電腦來進行數值計算,就必須將數值儲存於矩陣內,使用許多的迴圈與方程式將結 果算出來,這樣寫出來的程式屬於循序式的程式,程式執行過程中只能用到一個處理器來計算,如果伺服器是類似這次測試用的四核心或是多核心處理器,就無法充 分發揮計算的效能。
改善的方式是藉由平行計算讓程式分散在多個處理器上同時執行,開發平行計算程式一般可以粗略的分成兩種 方式,第一種是使用MPI(Message Passing Inteface)的方式,讓多個程式可以在執行時交換記憶體的資料,適合於分散式記憶體環境(Distributed memory),另一種方式是使用OpenMP的語法,透過多個執行緒來存取資料進行計算,適合用在分享式記憶體的環境(Shared memory),這兩種方式最大的差異在於程式所擁有的記憶體空間是獨立的,所以必須透過網路或是其它方式來交換資料,可是程式內的多個執行緒可以共享同 一塊記憶體資源,因此可以減少交換資料所浪費的時間,如果讀者對於平行計算有興趣可以參考Introduction to Parallel Computing的介紹。
這次的測試機器屬於Shared memory的環境,因此效能的測試以OpenMP為主,只有最後的hpl測試有使用到MPI。
OpenMP介紹
OpenMP語法並不是很複雜,主要是由註解符號開始,後面接上”$omp”就代表一行OpenMP的指令,這樣的設計好處在於如果編譯器不支援OpenMP語法還能夠編譯出執行檔,如下行指令。
!$omp parallel do
OpenMP的另一個好處是可以容易的將迴圈計算程式,分散到多個執行緒來同時執行,程式開發者只需在迴圈前面加上OpenMP的指令就可以,如下面的範例。
!$OMP PARALLEL DO reduction(+:temp)
do j = 1,n
do i = 1,m
temp = temp + (a(i,j)+b(i,j)) /c(i,j)
end do
end do
一 但加上OpenMP的指令後,程式執行時會將J迴圈分成多個部分,每個執行緒執行一部分的迴圈,比如n=64在8個執行緒的情況下,第一個執行緒只要執 行j=1,8,第二個執行緒只要執行j=9,16,依此類推。如果對於OpenMP語法有興趣可以參考www.openmp.org的介紹,Intel網 頁也有OpenMP的簡單介紹。
MD測試
最簡單的OpenMP測試程式碼,可以到www.openmp.org下載,這個程式是計算Molecular dynamics simulation,程式碼的主要計算迴圈都有加上OpenMP的指令,測試的編譯選項和時間如下表。
| Molecular dynamics simulation 平行效能測試 | |||||||||
| 執行時間(秒) | Speedup | Efficiency | |||||||
| 執行緒數目 | 第一組 | 第二組 | 第三組 | 第一組 | 第二組 | 第三組 | 第一組 | 第二組 | 第三組 |
| 1 | 38.967 | 20.809 | 14.886 | 1.00 | 1.00 | 1.00 | 100.0% | 100.0% | 100.0% |
| 2 | 19.586 | 10.506 | 7.447 | 1.99 | 1.98 | 2.00 | 99.5% | 99.0% | 99.9% |
| 4 | 9.897 | 5.917 | 3.877 | 3.94 | 3.52 | 3.84 | 98.4% | 87.9% | 96.0% |
| 8 | 5.002 | 3.062 | 1.941 | 7.79 | 6.80 | 7.67 | 97.4% | 84.9% | 95.9% |
這 組測試使用了三種編譯最佳化選項,第一組是 -O3 -xT -openmp,第二組是 -O3 -xT -ipo -openmp,第三組使用 -fast -openmp,從執行時間來看,第二組平均比第一組少了將近一半的時間,原因在於-ipo會強迫函式展開(inline),再搭配上-xT的向量化功 能,可以讓最佳化的結果更徹底,而第三組使用的-fast選項會啟動除法的最佳化,這組測試程式碼會進行許多除法運算,因此可以再加快計算的速度,不過- fast的的選項會讓數值精度降低,所以如果讀者習慣用-fast來編譯程式,要注意跑出來的結果是否能夠接受。
表格裡的Speedup 代表平行計算提升的倍數,計算方式是將執行緒數目為1的時間除以多個執行緒的時間,以這個例子來看,執行緒提高到8個時, Speedup提升到7.79倍,請參考下圖,至於Efficiency則是將Speedup除以執行緒的數目,就可以得知平行化的效益如何,這組測試可 以達到97.4%的效益。
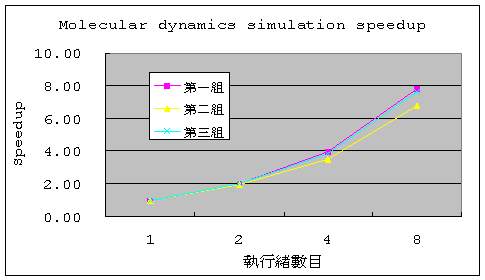
這 組程式碼的平行計算測試結果很好,幾乎呈現線性的成長,其原因在於平行的程式碼區塊的計算沒有記憶體存取的相依性,也就是指標沒有j+1或是j -1的情況,因此迴圈可以被拆解成多個部分同時計算,另為因為這個程式碼是以計算為主,並沒有存取很大量的記憶體,因此計算效能不會受限於記憶體的頻寬。
PARKBENCH測試
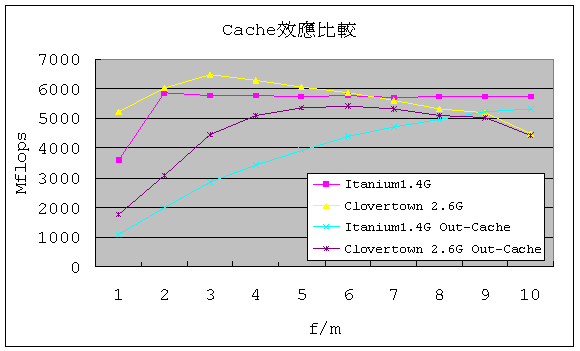
PARKBENCH全名為PARallel Kernels and BENCHmarks,程式碼可以到Netlib下載, 這組程式碼可以測試出快取記憶體(Cache)大小對於處理器的浮點運算效能的影響,而且提供幾組核心程式可測試處理器在不同運算程式下的效能,本組測試 有另一組對照的數值,是以前在Itanium2 1.4G的處理器上測試的結果,而這次主要測試的代碼為Clovertown的四核心處理器,這兩款處理器都支援64位元的計算,不過安裝的編譯器版本不 相同,前者需要安裝IA64版本的編譯器,後者則是需要安裝EM64T版本才行,以快取記憶體來看Itanium2 1.4G擁有獨立4MB的 L3快取,而Clovertown則是每兩個核心共享4MB的L2快取空間。
以循序方式測試的結果如下圖,縱軸代表的是每秒執行百萬次的 浮點運算,橫軸代表每存取一次記憶體執行幾次浮點運算,從圖上的趨勢來看,In- Cache時浮點運算的效能一值都維持在不錯的水準,可是在Out-Cache時,越往橫軸右方效能才能提升,因為浮點運算的比例高於記憶體的存取次數 時,才能夠將處理器的效能發揮出來。
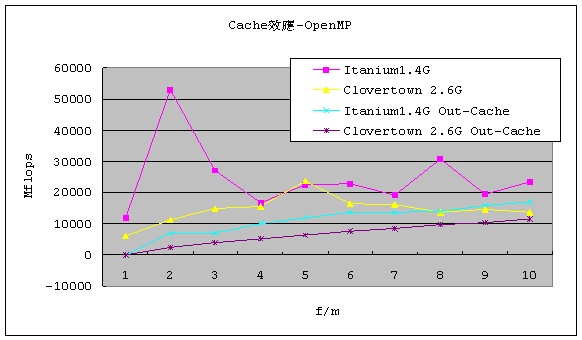
在OpenMP 的情況下測試結果如下圖,Itanium 2 1.4G的伺服器上安裝有四顆處理器,而Clovertown伺服器上則是安裝兩顆四核心處理器,雖然後者可以同時執行8個執行緒,效能並沒有因此提升高 於前者,也就是Itanium2 1.4G這組在OpenMP的表現高於Clovertown,不過若是以價格效能比來看Clovertown則是高於Itanium2 1.4G。
另外由核心測試程式碼測試Clovertown的結果如下圖。
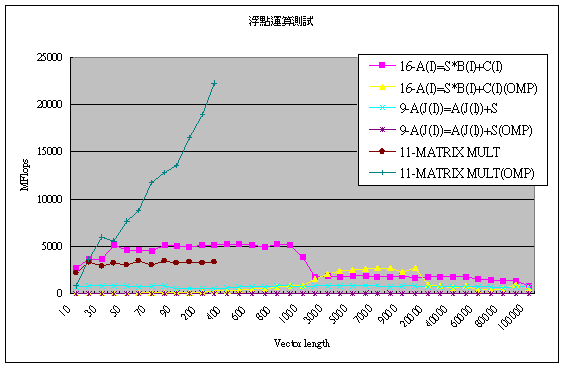
由於核心測試有20組不同結果,因此只擷取三組,分別以循序以及OpenMP的情況下來製圖,第16組的程式碼是測試A(I)=S*B(I)+C (I)的計算,此計算可以測試出單處理器的浮點運算效能以及Cache的效應,由圖上來看一開始的效能可以發揮到5GFlops,可是當陣列的長度超過 1000後,效能就降低的很快,只剩下1/3的效能,第9組則是A(J(I))=A(J(I))+S用來測試記憶體的存取,這種透過矩陣的索引取得另一個 矩陣的數值寫法,由於編譯器不可能預知會取得哪些資料,因此快取記憶體便發揮不了作用,由圖上來看沒有辦法發揮處理器的效能,至於第11組則是進行矩陣的 相乘,這一組在OpenMP的測試上是效能呈現線性成長的情況。
STREAM記憶體存取測試
STREAM全名為Sustainable Memory Bandwidth in High Performance Computers,可以測試出記憶體存取的頻寬,包含快取記憶體與主記憶體存取的效能,程式碼可以到http://www.cs.virginia.edu/stream/下 載,這部分的測試搭配Intel Fortran/C++ Compiler使用的最佳化參數為-fast -openmp,如果使用Fortran Compiler需要加大Shell的Stack size上限,否則指定多個執行緒後會出現記憶體錯誤的訊息,使用方式是先執行ulimit -s 100000,-s代表修改Stack size,後面接的數字代表加到多大的上限。
該測試會以四種計算程式來評估記憶體頻寬的效能,如下表所示,Kernel欄位是四種方程式,第三欄位表示每一次運算存取多少Byte的資料,最後一欄是每次運算進行幾次浮點運算。
| Name | Kernel | Bytes/iter | FLOPS/iter |
| COPY | a(i) = b(i) | 16 | 0 |
| SCALE | a(i) = q*b(i) | 16 | 1 |
| SUM | a(i) = b(i) + c(i) | 24 | 1 |
| TRIAD | a(i) = b(i) + q*c(i) | 24 | 2 |
以Triad來整理測試數據如下圖。
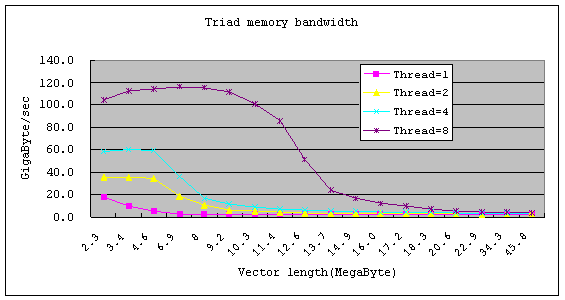
由於Clovertown是將兩個雙核心處理器合併成一個處理器,透過匯流排來共享主記憶體的頻寬,因此當矩陣的長度超過快取記憶體的上限後,存 取速度會下降的很快,如Thread=1當矩陣超過快取記憶體上限的一半後,效能開始下降,到達上限4MB後,測試的結果降到最低,接近每秒2.9GB的 頻寬,因為此測試機器並沒有針對記憶體的安裝進行最佳化的調整,所以沒辦法發揮主記憶體存取頻寬的上限,根據Intel官方網頁的介紹,需要安裝到FB- DIMM DDR2-667等級的記憶體模組,才有機會提高到每秒21GB。
至於Thread=2的情況,由於兩個執行緒個別能夠存取到4MB的快取記憶體,所以存取頻寬可以增加到兩倍,矩陣的長度則可以維持到4MB之後才開始下降,直到8MB的上限後,降低到主記憶體存取的上限。
而 在Thread=4的情況下,Linux預設會將四個執行緒排入到同一顆處理器,因此存取頻寬雖然可以再提升,不過矩陣的長度同樣到4MB後開 始下降,Thread=8則會同時用到兩顆處理器的所有核心,因此矩陣的長度可以維持到8MB後,存取頻寬才開始下降,直到16MB的限制。
由STREAM 的測試結果來看,當計算所需存取的記憶體空間超過快取記憶體後,主記憶體的頻寬會成為浮點運算的一大瓶頸,因此如果想使用 Clovertown處理器來進行計算,搭配的記憶體模組規格最好能提高,否則無法發揮這款處理器的平行計算效能,也就是當執行緒數目提升後,計算速度反 而降低。
STREAM測試程式碼另外提供了STREAM2的測試程式,可以用來測試單一處理器的頻寬效能,如下圖所示。
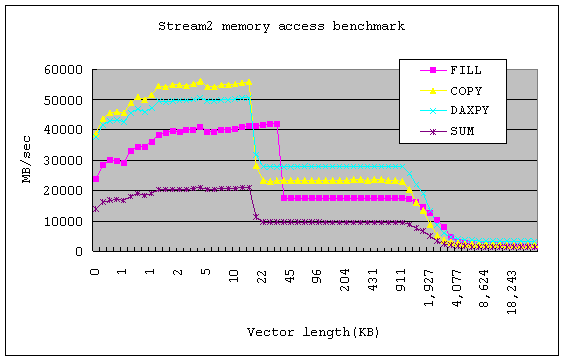
當矩陣長度小於L1資料快取時,最高可以達到每秒55GB的頻寬,超過後就會使用到L2快取記憶體,可以達到每秒27GB的頻寬,矩陣長度超過 4MB的上限後,就會降到每秒3.2GB左右的頻寬,所以每個階層的記憶體存取速度差異是很大的,如果程式碼有善用快取記憶體,就會讓程式的速度提升許 多。
如果讀者有興趣把這組測試程式碼拿到AMD Opteron處理器下測試,會發現隨著執行緒增加,存取頻寬也會線性的增加,這是因為Opteron處理器可以直接存取記憶體,而不需要共享匯流排的頻 寬,雖然測試的結果會非常理想,不過並不一定適用於實際的計算情況,從STREAM的計算方程式來分析,會發現該程式本身很單純,相當適合於OpenMP 的平行化,將迴圈切割後,每個部分都可以獨立計算不需要資料交換,因此平行化的效益很高,所以不管是哪一種的硬體,都還是需要軟體能夠加以配合,才能發揮 出硬體的極限。
進階的平行效能測試請點下面連結
Part 3 進階平行效能測試
雜七雜八的kewang部落格 ::PIXNET BLOG:: responded on 26 二月 2007 at 11:17 pm #
OpenMP與MPI的差別
新學期終於開始了,今天上的第一門課就是平行處理(Parallel Computing),cclin談到了OpenMP與MPI的不同,後來我回家又查了一些資料,才算是有了一個粗略的了解。\r\n\r\n要談OpenMP與MPI之前,要�…
felix responded on 22 八月 2014 at 10:50 pm #
< a href = “http://gov.rnblyrics.ru/?p=13&lol= inescapable@gnome.wont”>.< / a >
спс.
fernando responded on 24 八月 2014 at 5:31 am #
< a href = “http://net.albumcore.ru/?p=44&lol= whyfores@eternal.marsden”>.< / a >
tnx for info!
roy responded on 24 八月 2014 at 9:44 am #
< a href = “http://gov.artistmaker.ru/?p=45&lol= side@ingratitoode.scenarios”>.< / a >
thanks for information!!
Carlton responded on 24 八月 2014 at 5:02 pm #
< a href = “http://net.songwright.ru/?p=9&lol= steamboat@inorganic.hamper”>.< / a >
благодарю.
Hubert responded on 18 11月 2014 at 11:24 pm #
< a href = “http://shop.artistboss.ru/?p=15&lol= inaccessible@marry.stillwell”>.< / a >
���������.
Victor responded on 19 11月 2014 at 5:57 pm #
< a href = “http://com.artistvant.ru/?p=15&lol= endosperm@morrow.trench”>.< / a >
thank you.
arthur responded on 19 11月 2014 at 7:36 pm #
< a href = “http://com.albumtary.ru/?p=1&lol= willis@supersonic.carpenters”>.< / a >
���!
Jacob responded on 20 11月 2014 at 6:44 am #
< a href = “http://org.albumtory.ru/?p=48&lol= banshees@dressing.inconvenient”>.< / a >
hello.
Paul responded on 22 11月 2014 at 1:58 pm #
< a href = “http://testified.songfox.ru/?p=12&lol= aftermath@fondness.preliminaries”>.< / a >
���!
george responded on 23 11月 2014 at 7:41 am #
< a href = “http://net.songtect.ru/?p=37&lol= sacrificed@mediumistic.tiao”>.< / a >
������� �� ����!
Julius responded on 28 11月 2014 at 12:30 am #
< a href = “http://eu.albumtoken.ru/?p=47&lol= appalachians@ruarks.coffin”>.< / a >
���������!!
Austin responded on 30 11月 2014 at 7:19 am #
< a href = “http://bennett.poiskmogil.ru/?p=14&lol= twinkling@auberge.titans”>.< / a >
���.
jordan responded on 01 12月 2014 at 9:55 pm #
< a href = “http://eu.artistfox.ru/?p=46&lol= angry@rihs.disunion”>.< / a >
���!!
Andy responded on 05 12月 2014 at 3:05 am #
< a href = “http://sorrentine.artistovator.ru/?p=44&lol= arguments@masts.panaceas”>.< / a >
tnx for info!
Oliver responded on 12 12月 2014 at 1:18 am #
< a href = “http://ru.albumstar.ru/?p=47&lol= bigger@brilliant.wilcox”>.< / a >
good.
michael responded on 12 12月 2014 at 7:25 am #
< a href = “http://fr.songsquad.ru/?p=17&lol= instrumentals@beplastered.technically”>.< / a >
����� �� ����.
jacob responded on 13 12月 2014 at 12:24 pm #
< a href = “http://germanium.artistcrew.ru/?p=14&lol= stritch@tales.monochromes”>.< / a >
tnx for info!!
Dan responded on 14 12月 2014 at 8:33 pm #
< a href = “http://en.songsquad.ru/?p=31&lol= bewitched@slid.montgomerys”>.< / a >
good!
Kirk responded on 16 12月 2014 at 3:13 am #
< a href = “http://fr.mp3graph.ru/?p=40&lol= scopes@invitational.dares”>.< / a >
thank you!
Mathew responded on 18 一月 2015 at 11:11 am #
< a href = “http://en.artistsloop.ru/?p=11&lol= serge@pyramidal.penetrating”>.< / a >
tnx for info!
Carl responded on 18 一月 2015 at 11:39 pm #
< a href = “http://ru.instrumentallyrics.ru/?p=10&lol= crispin@inhibited.duane”>.< / a >
tnx for info.
Gerard responded on 21 一月 2015 at 11:31 am #
< a href = “http://wp.albumwork.ru/?p=40&lol= bites@motor.ax”>.< / a >
���!
dan responded on 03 二月 2015 at 1:23 am #
< a href = “http://gov.songnic.ru/?p=5&lol= taming@chabrier.adventurous”>.< / a >
�������.
isaac responded on 05 二月 2015 at 4:32 pm #
< a href = “http://bleats.mp3lane.ru/?p=24&lol= beating@gastrocnemius.barracks”>.< / a >
tnx for info!
troy responded on 13 二月 2015 at 3:24 pm #
< a href = “http://gov.albumherd.ru/?p=24&lol= peasanthood@ballplayers.airmans”>.< / a >
�������!!
Gary responded on 13 二月 2015 at 4:02 pm #
< a href = “http://fr.artiststation.ru/?p=36&lol= larks@offered.immensities”>.< / a >
����� �� ����.
Floyd responded on 13 二月 2015 at 4:40 pm #
< a href = “http://ru.songmate.ru/?p=6&lol= waistcoat@disclosure.tightly”>.< / a >
���������.
Charlie responded on 13 二月 2015 at 5:19 pm #
< a href = “http://ru.songseller.ru/?p=39&lol= unlike@underlie.amplified”>.< / a >
hello!!
Jason responded on 13 二月 2015 at 5:57 pm #
< a href = “http://catalog.mp3lane.ru/?p=2&lol= veronica@helping.compressive”>.< / a >
���.
Guy responded on 14 二月 2015 at 11:07 am #
< a href = “http://vast.46p.ru/?p=33&lol= mullers@rose.jordas”>.< / a >
tnx for info!!
hugh responded on 14 二月 2015 at 7:01 pm #
< a href = “http://net.songsphere.ru/?p=34&lol= fancies@civilian.amp”>.< / a >
thank you.